
Last time, we covered the basic principles of dynamic programming and examined how we could use it to greatly enhance the runtime efficiency for calculating the value of the nth item in the fibonacci sequence. This time, we’ll outline a general approach for handling dynamic programming problems, and take a look at how we can use this approach to tackle a new problem — finding the minimum edit distance between two strings. Onward!
The 5 Step Process
According to this excellent series of videos from MIT OpenCourseWare, anytime you need to solve a DP problem, you can break it down into the following five steps.
- Define what subproblems need to be solved.
- Determine what you need to guess.
- Express the relationship between subproblems.
- Recurse and memoize.
- Solve the original problem.
Let’s go over these steps one by one, and see how they apply to our fibonacci algorithm from before.
(1) Define what subproblems need to be solved
The general rule when defining subproblems is that each subproblem needs to have the same structure as the original problem. There are two main approaches to this: prefixes/suffixes, or subsequences. These approaches both involve breaking down the original problem into smaller subproblems, but they differ in terms of how they make the subproblem smaller.
Prefix/suffix subproblems are made smaller by popping items off either the beginning or the end of the input sequence. This is essentially what we did with the fibonacci algorithm — while we weren’t working with a proper input sequence per se (like a string or array), we accomplished something similar by calculating fib() with progressively smaller values of n. Each recursive call to fib() could thus be viewed as operating on a prefix of the original problem.
Subsequence subproblems, on the other hand, are made smaller by removing items from both ends of the original sequence. We won’t look at any problems that use this approach here, but a good example of it is parenthesization for matrix multiplication.
Also involved in this step is determining the number of subproblems which will need to be solved. Generally, prefixes/suffixes will give you nsubproblems, while subsequences result in n² subproblems. In the case of fibonacci, since we were using quasi-prefixes, there were n subproblems.
(2) Determine what you need to guess
DP is oftentimes used for optimization problems, and optimization typically involves picking either the minimum or maximum value from a group of potential options. Since presumably we don’t already know which option is best, the only way to find out is to try, or “guess”, them all. By analyzing the problem, we should be able to deduce the number of guesses that will need to be made per subproblem. The fibonacci algorithm did not involve guessing, but the edit distance problem we’ll soon be looking at will.
(3) Express the relationship between subproblems
The value of each subproblem can be calculated as some combination of the results of other subproblems, and this is where we explicitly define how that will work. With fibonacci, this was easy… it comes from the definition of the fibonacci sequence itself. For some value k where 0 ≤ k ≤ n, fib(k) = fib(k-1) + fib(k-2).
This is also where we determine how much time it will take to calculate the solution for each subproblem will take once all the requisite recursive calls have been resolved. In the case of the fibonacci sequence, this is constant, or O(1) time, because once the values of the subproblems are calculated, all you need to do is add them together.
(4) Recurse and memoize
Once we know how the subproblems relate to each other, the next step is to flush out the algorithm by adding memoization (and base cases, if taking the recursive approach). This should hopefully be fairly straight forward, if the previous steps have been properly followed. But there’s also one important thing we need to check — namely, we need to ensure that our subproblem dependency DAG is properly acyclic.
A DAG is a directed acyclic graph. Directed means that the edges (or “connections”) between the vertices (or “nodes”) go in a specific direction, and acyclic means that, well, there are no cycles in the graph. If you recall, we actually already constructed a subproblem dependency DAG for the fibonacci sequence when we built out its recursion tree:
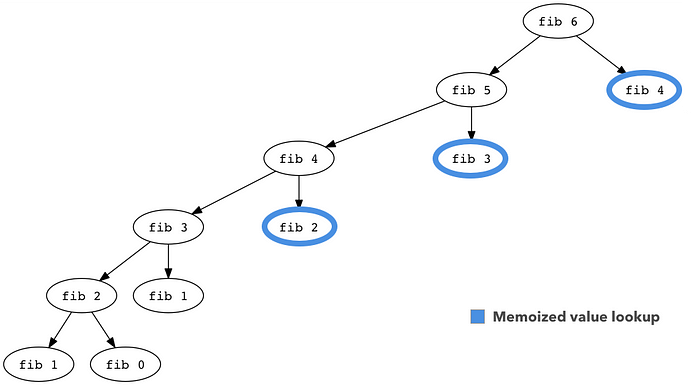
The reason it’s important that the DAG lives up to its name and doesn’t have any cycles is because if you try perform DP on a graph with cycles, the algorithm’s time and space complexity become infinite. Consider the following graph:
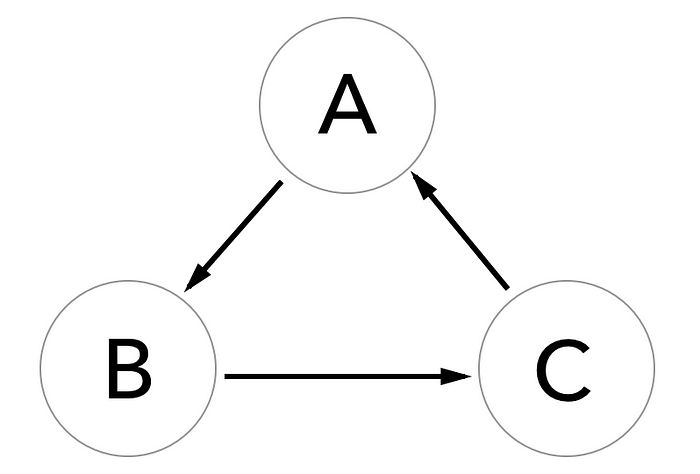
What happens if we try to run some dynamic programming on this graph? Well, the value of A depends on B, which depends on the value of C, which in turn depends on the value of A again, and… oh no. Because there’s a cycle, no value ever gets memoized for lookup, and we end up with an infinite loop.
Of course, it’s possible to take an cyclic graph and make it acyclic by “exploding” it into multiple, limited iterations. This is the approach taken by the Bellman Ford algorithm, for instance.
(5) Solve the origin problem
This step can oftentimes be trivial, but sometimes there’s just a little bit of extra work that needs to happen to actually derive the solution to the original problem from the subproblems. This wasn’t required with the fibonacci sequence, but sometimes it is necessary, so it’s an important step to keep in mind.
Here we can also examine the overall running time of our algorithm, which is typically the number of subproblems multiplied by the time it takes to solve each subproblem. In the case of the fibonacci algorithm, we had nsubproblems each of which took constant time to resolve, for a total running time of O(n).
That’s it! Now that we’ve articulated a general formula for DP problems, let’s see if we can apply this methodology to an example case: finding the minimum edit distance between two strings.
Edit Distance
The premise is this: given two strings, we want to find the minimum number of edits that it takes to transform one string into the other. There are three edit operations we can use to transform a string: we can insert a character, remove a character, or substitute a character. Each operation has an associated cost — insertions and removals each cost 1, and substitutions cost either 1 or 2, depending on whether or not you consider a substitution to essentially be just a removal followed by an insertion. When the substitution cost is 2, the result is known as the Levenshtein distance, named after Vladimir Levenshtein, the author of the original algorithm.
For example, the edit distance between ‘hello’ and ‘hail’ is 3 (or 5, if using Levenshtein distance):
- Substitute ‘e’ for ‘a’ →
hallo - Substitute the following ‘i’ for ‘l’ →
hailo - Remove the final ‘o’ →
hail
As another example, the edit distance between ‘intrinsic’ and ‘intrusive’ is 4 (or 6, in Levenshtein distance):
- Substitute the second ‘i’ in ‘intrinsic’ for a ‘u’ →
intrunsic - Remove the following ’n’ →
intrusic - Substitute the final ‘c’ for a ‘v’ →
intrusiv - Insert an ‘e’ at the end →
intrusive
Let’s see how we can express the solution to this in code, using the steps outlined above.
(1) Define what subproblems need to be solved
When we recurse over the input sequence (or work through it iteratively with the bottom-up approach), we’re essentially going to be saying “figure out what to do with the first (or last) character, then compute the result by adding together the cost of that and everything that comes after (or before)”. From this, we can deduce that we’re going to be working with prefixes/suffixes. What makes this problem interesting is that there are actually two strings we need to work through. So the total number of subproblems will be n * m, where n is the length of the first string and m is the length of the second.
(2) Determine what you need to guess
For each subproblem, we’ll need to make a choice — whether to insert, remove, or substitute a character. This is presuming, of course, that the characters we’re comparing are not already equal, in which case we want to do nothing.
(3) Express the relationship between subproblems
Let’s look at how we could formally express the ideas we’ve already come up with in code:
indexA = 0;
indexB = 0;if (strA.charAt(indexA) == strB.charAt(indexB) {
return recurse(strA, strB, indexA + 1, indexB + 1);
}return min(
1 + recurse(strA, strB, indexA, indexB + 1) // insertion
1 + recurse(strA, strB, indexA + 1, indexB) // removal
2 + recurse(strA, strB, indexA + 1, indexB + 1) // substitution
)
This is taking a suffix approach, and using Levenshtein distance as indicated by a cost of 2 for substitution. From this, we can infer that the time it will take to resolve each subproblem is constant, as all we’ll need to do is take the minimum of 3 values. When I was first looking at this, it was difficult for me to intuit how inserting a character in one string translates to incrementing the index for the other string (and so on for the other operations). So let me try and explain it for those who might be in the same boat.
First of all, there’s no need for explicit string comparisons here. When ‘inserting’ a character, it’s presumed that the character inserted into strA at indexA will be the one in strB at indexB. Once an ‘insertion’ has been made, we have to figure out what to compare next. We’ve already handled the character in strB at indexB, so we can advance the index there. But we haven’t addressed the character in strA at indexA, so we don’t advance indexA. This is perhaps a little confusing, since we’re used to insertions altering indexes… but remember, strA was not actually altered in any way, so the character pointed at by indexA remains the same.
Likewise, we’re able to emulate ‘removing’ the character in strA at indexAby advancing the iterator for that string and not the other. Since substitutions are essentially a removal followed by an insertion, that operation ends up advancing both indexes. And of course, if the characters at the given indexes in both strings are the same, there’s no operation to be performed so we can advance both indexes in that case as well. Given that no edits are actually being made to the strings, incrementing the indexes is mostly about determining which characters need to be ‘handled’ next.
(4) Recurse and memoize
Now the fun part — adding base cases and flushing out the algorithm. Looking at how we’ve laid out the structure of our solution, it’s fairly evident that there are no circular dependencies, so our DAG should indeed be acyclic (if this isn’t clear to you, I’d recommend graphing out the recursion tree like we did with the fibonacci algorithm).
Here’s the naive solution, without memoization, written out in Java:
import java.util.*;
class NaiveEditDistance {
static int min(int insert, int remove, int replace) {
Integer[] values = { insert, remove, replace };
return Collections.min(Arrays.asList(values));
}
static int calculateEditDistance(String str1, String str2, int i, int j) {
// If i is 0, we're essentially looking at an empty substring of str1.
// To convert an empty substring to any other string, you just insert
// every character from the other string. Since the only operation to be
// performed is insertion, the cost is equal to the length of the other
// string.
if (i == 0) {
return j;
}
// This goes the other way as well of course — if you need to get from
// some substring to an empty string, The shortest path is to simply
// remove every character in the substring.
if (j == 0) {
return i;
}
// If the characters in the strings at a particular value of i and j match,
// then we don't need to perform any operation and the cost is 0. Since
// Java is a 0-indexed language, we need to subtract 1, otherwise we'd
// get a StringIndexOutOfBoundsException.
if (str1.charAt(i - 1) == str2.charAt(j - 1)) {
return calculateEditDistance(str1, str2, i - 1, j - 1);
}
// Otherwise, we need to recurse. Note that we're using Levenshtein
// distance here.
return min(1 + calculateEditDistance(str1, str2, i, j - 1), // insert
1 + calculateEditDistance(str1, str2, i - 1, j), // remove
2 + calculateEditDistance(str1, str2, i - 1, j - 1)); // substitute
}
public static void main(String[] args) {
String str1 = "intrinsic";
String str2 = "intrusive";
int minDistance = calculateEditDistance(
str1, str2, str1.length(), str2.length()
);
System.out.println(minDistance);
}
}
view rawNaiveEditDistance.java hosted with ❤ by GitHub
The output of this gist should be 6. Note that we’ve switched it around here — instead of using suffixes, we’re using prefixes. This is simply because it makes handling the base cases easier… otherwise, it’s pretty much exactly the same deal as before, just in reverse.
However, this isn’t very efficient — we’re unnecessarily recursing over subproblems we’ve already calculated the optimal value for. Let’s add some memoization to improve things:
import java.util.*;
class DPEditDistance {
static int min(int insert, int remove, int replace) {
Integer[] values = { insert, remove, replace };
return Collections.min(Arrays.asList(values));
}
static int calculateEditDistance(String str1, String str2, int i, int j, int[][] memo) {
// A value of greater than -1 in the memo grid means that the value for
// this combination of i and j has already been calculated and can be
// promptly returned.
if (memo[i][j] > -1) return memo[i][j];
if (i == 0) {
memo[i][j] = j;
return j;
}
if (j == 0) {
memo[i][j] = i;
return i;
}
if (str1.charAt(i - 1) == str2.charAt(j - 1)) {
memo[i][j] = calculateEditDistance(str1, str2, i - 1, j - 1, memo);
return memo[i][j];
}
memo[i][j] = min(1 + calculateEditDistance(str1, str2, i, j - 1, memo), // insert
1 + calculateEditDistance(str1, str2, i - 1, j, memo), // remove
2 + calculateEditDistance(str1, str2, i - 1, j - 1, memo)); // substitute
return memo[i][j];
}
public static void main(String[] args) {
String str1 = "intrinsic";
String str2 = "intrusive";
// When generating the memo, we need an extra row and column to accomodate
// empty substrings.
int[][] memo = new int[str1.length() + 1][str2.length() + 1];
// int arrays in Java are initialized with 0 values, but 0 in this
// context means that no changes are needed. We need another value to
// represent an unmemoized value, so we'll fill the memo with -1 values
// instead.
for (int[] row : memo)
Arrays.fill(row, -1);
int minDistance = calculateEditDistance(
str1, str2, str1.length(), str2.length(), memo
);
System.out.println(minDistance);
}
}
view rawDPEditDistance.java hosted with ❤ by GitHub
This works fine but is awfully verbose. We can tidy things up a bit by switching from the recursive to the iterative approach, using bottom-up DP:
import java.util.*;
class BottomUpEditDistance {
static int min(int insert, int remove, int replace) {
Integer[] values = { insert, remove, replace };
return Collections.min(Arrays.asList(values));
}
static int calculateEditDistance(String str1, String str2) {
int[][] memo = new int[str1.length() + 1][str2.length() + 1];
for (int i = 0; i <= str1.length(); i++) {
for (int j = 0; j <= str2.length(); j++) {
if (i == 0) {
memo[i][j] = j;
}
else if (j == 0) {
memo[i][j] = i;
}
else if (str1.charAt(i - 1) == str2.charAt(j - 1)) {
memo[i][j] = memo[i - 1][j - 1];
}
else {
memo[i][j] = min(1 + memo[i][j - 1],
1 + memo[i - 1][j],
2 + memo[i - 1][j - 1]);
}
}
}
return memo[str1.length()][str2.length()];
}
public static void main(String[] args) {
String str1 = "intrinsic";
String str2 = "intrusive";
int minDistance = calculateEditDistance(str1, str2);
System.out.println(minDistance);
}
}
view rawBottomUpEditDistance.java hosted with ❤ by GitHub
To gain an intuition for how we’re building up this memo matrix, I’d recommend taking a look at this excellent video here.
(5) Solve the origin problem
Fortunately, once we’ve tabulated the results from all our subproblems we don’t really have to do any extra work to solve our original problem. But we can still calculate the overall time and space complexity of our algorithm. Once again, for dynamic programming problems this is usually the number of subproblems multiplied by the time taken per subproblem. As we already covered in the previous steps, the number of subproblems is n * m, where nis the length of the first string and m is the length of the second, and each subproblem takes constant time to resolve. So the overall time complexity of this algorithm is n * m, and the same goes for the space complexity, since we need n * m space in our memo table. Not so bad!
Conclusion
We’ve successfully examined how we can use a standardized methodology to tackle a non-trivial dynamic programming question. But of course, there is so much more to explore about this topic! If you’re interested, I would highly recommend this video series from MITOpenCourseWare. Of course, reading and watching about dynamic programming will only get you so far… to really learn these things, you have to practice. For that, I’ve found that the exercises in Cracking the Coding Interview are a truly fantastic resource.
